I've used Claude Code daily since it came out. Here are the best practices, tools, and configuration patterns I've picked up. Most of this applies to other coding agents (Codex) too.
TL;DR
My configs, plugins, and skills for Claude Code:
https://github.com/vinta/hal-9000
CLAUDE.md
The Global CLAUDE.md
Your ~/.claude/CLAUDE.md should only contain:
- Your preferences and nudges to correct agent behaviors
- You probably don't need to tell it YAGNI or KISS. They're already built in
Pro tip 1: before adding something to CLAUDE.md, ask it, "Is this already covered in your system prompt?"
Pro tip 2: try my refactor-claude-md skill!
Here are some parts of my CLAUDE.md I found useful:
<use_ask_user_question>
When you need input and the answer is a selection rather than a sentence (multiple-choice, yes/no confirmations that gate next steps, picking from a list, choosing between approaches), ask with the AskUserQuestion tool instead of plain text, so the user clicks an option instead of typing.
When presenting approaches, put the summary in each option's label and the pros/cons in its description. Plain text is fine when the answer is open-ended. This changes the format of questions, not whether to ask: never use it to ask permission for work you already have enough information to do.
</use_ask_user_question>
<prefer_online_sources>
Training data goes stale: library/framework/SDK APIs, config keys, CLI flags, cloud services, platform features, syntax, and versions change, and guessing has repeatedly cost debugging round-trips.
Invoke the find-docs skill BEFORE writing code or config that touches any of those, and BEFORE answering questions about them. Being about to write such code is trigger enough, even when no question was asked. Confidence is not an exemption, and neither is the library being well known. Answering from training data, or fetching a remembered docs URL instead of invoking the skill, does not satisfy this rule.
If the user provides URLs, WebFetch each one as a primary source before searching further. Never skip user-provided URLs. For topics find-docs covers poorly, WebFetch the official docs instead of falling back to training data.
</prefer_online_sources>
<auto_commit if="you have completed the user's requested change">
Use the commit skill to commit, always passing a brief description of what changed (e.g. /commit add login endpoint). Don't batch unrelated changes into one commit.
</auto_commit>
Also see:
The Project CLAUDE.md
For project-specific instructions, put them in the project-level CLAUDE.md.
The highest-signal content in your project CLAUDE.md (or any skill) is the Gotchas section. Build these from the failure points Claude Code actually runs into.
Also see:
Per File Type Rules
For language-specific or per-file rules, put them in ~/.claude/rules/, so Claude Code only loads them when editing those file types.
For instance, ~/.claude/rules/typescript-javascript.md:
---
paths:
- "**/*.{ts,tsx}"
- "**/*.{js,jsx}"
- "**/package.json"
---
# TypeScript / JavaScript
- Pin exact dependency versions in package.json — no ^ or ~ prefixes
- Use node: prefix for Node.js built-in modules (e.g., node:fs, node:path)
- Write proper types/interfaces instead of any or casts like as any / as unknown. When a value is genuinely untypable, use unknown and narrow it explicitly. any is the last resort when no typed alternative exists
- Prefer interface over type for object shapes (extendable, better error messages)
- Avoid enums. Use union types (type Status = 'active' | 'inactive') or as const objects
- Mark properties and parameters readonly when they should not be mutated
- Do not add explicit return types. Let TypeScript infer them
- Use the typescript LSP tool for type-aware code navigation when grep's text matching would be ambiguous
The full rules I have:
Configurations
Settings
There are some useful configurations you could set in your ~/.claude/settings.json:
{
"env": {
"CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "1",
"CLAUDE_CODE_EFFORT_LEVEL": "max",
"DISABLE_ERROR_REPORTING": "1",
"DISABLE_EXTRA_USAGE_COMMAND": "1",
"DISABLE_FEEDBACK_COMMAND": "1"
},
"permissions": {
"allow": ["..."],
"deny": ["..."],
"ask": ["..."],
"defaultMode": "auto"
},
"cleanupPeriodDays": 365,
"model": "opus[1m]",
"advisorModel": "fable",
"enableWorkflows": true,
"showClearContextOnPlanAccept": true,
"skipAutoPermissionPrompt": true,
"teammateMode": "tmux",
"voiceEnabled": true
}
Highlights:
"CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "1": Enable Agent Team feature, a fancy way to consume a huge amount of tokens"permissions.defaultMode": "auto": We use this to pretend it's safer than --dangerously-skip-permissions"cleanupPeriodDays": 365: By default, your chat history (location: ~/.claude/projects/) will be deleted after 30 days"voiceEnabled": true: Enable Voice Dictation feature. Code like a boss!
The full settings I use:
Permissions
If you're not using a sandbox or devcontainer for Claude Code, you may want to block some evil commands in your ~/.claude/settings.json:
{
"permissions": {
"deny": [
"Read(~/.aws/**)",
"Read(~/.config/**)",
"Read(~/.docker/**)",
"Read(~/.dropbox/**)",
"Read(~/.gnupg/**)",
"Read(~/.gsutil/**)",
"Read(~/.kube/**)",
"Read(~/.npmrc)",
"Read(~/.orbstack/**)",
"Read(~/.pypirc)",
"Read(~/.ssh/**)",
"Read(~/*_history)",
"Read(~/**/*credential*)",
"Read(~/Library/**)",
"Edit(~/Library/**)",
"Read(~/Dropbox/**)",
"Edit(~/Dropbox/**)",
"Read(//etc/**)",
"Edit(//etc/**)",
"Bash(su *)",
"Bash(sudo *)",
"Bash(passwd *)",
"Bash(env *)",
"Bash(printenv *)",
"Bash(history *)",
"Bash(fc *)",
"Bash(eval *)",
"Bash(exec *)",
"Bash(rsync *)",
"Bash(sftp *)",
"Bash(telnet *)",
"Bash(socat *)",
"Bash(nc *)",
"Bash(ncat *)",
"Bash(netcat *)",
"Bash(nmap *)",
"Bash(kill *)",
"Bash(killall *)",
"Bash(pkill *)",
"Bash(chmod *)",
"Bash(chown *)",
"Bash(chflags *)",
"Bash(xattr *)",
"Bash(diskutil *)",
"Bash(mkfs *)",
"Bash(security *)",
"Bash(defaults *)",
"Bash(launchctl *)",
"Bash(osascript *)",
"Bash(dscl *)",
"Bash(networksetup *)",
"Bash(scutil *)",
"Bash(systemsetup *)",
"Bash(pmset *)",
"Bash(crontab *)"
],
"ask": [
"Bash(curl *)",
"Bash(wget *)",
"Bash(open *)",
"Bash(* install *)",
"Bash(bun add *)",
"Bash(yarn add *)",
"Bash(pnpm add *)",
"Bash(uv add *)",
"Bash(git push *)",
"Bash(npx supabase db *)"
]
},
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "python3 ~/.claude/hooks/guard-bash-paths.py"
}
]
}
]
}
}
However, "deny": ["Read(~/.aws/**)", "Read(~/.kube/**)", ...] alone is not enough, since Claude Code can still read sensitive files through the Bash tool. You can write a simple hook to intercept Bash commands that access blocked files, like this guard-bash-paths.py hook.
Though, Claude Code can still write a one-time script to read sensitive data and bypass all of the above defenses. So the safest approach is using sandbox after all.
Plugins
Claude Code Plugins are simply a way to package skills, commands, agents, hooks, and MCP servers. Distributing them as a plugin has the following advantages:
- Auto update (versioned releases)
- Auto hooks configuration (users don't need to edit their
~/.claude/settings.json manually)
- Skills have a
/plugin-name:your-skill-name prefix (no more conflicts)
To install a plugin, you need to add a marketplace first. A marketplace is usually just a GitHub repo. Think of it as a namespace.
/plugin marketplace add anthropics/skills
/plugin marketplace add openai/codex-plugin-cc
/plugin marketplace add mattpocock/skills
/plugin marketplace add vinta/hal-9000
# browse plugins
/plugin
Recommended:
Skills
Skills can contain executable scripts and hooks, not just Markdown. Use with caution! When in doubt, have your agent review them first.
Here are skills I use, mostly installed per project when needed:
# my skills
npx skills add https://github.com/vinta/hal-9000 --skill commit blindspot best-practices simple-english refactor-agents-md -g
npx skills add https://github.com/vinta/dear-ai
# workflow skills
npx skills add https://github.com/mattpocock/skills -g
# writing skills
npx skills add https://github.com/softaworks/agent-toolkit --skill writing-clearly-and-concisely humanizer naming-analyzer
npx skills add https://github.com/hardikpandya/stop-slop
npx skills add https://github.com/shyuan/writing-humanizer
# doc skills
npx skills add https://github.com/upstash/context7 --skill find-docs -g
# LLM API skills
npx skills add https://github.com/openai/skills
npx skills add https://github.com/google-gemini/gemini-skills
# backend skills
npx skills add https://github.com/trailofbits/skills --skill modern-python
npx skills add https://github.com/trailofbits/skills-curated --skill python-code-simplifier
npx skills add https://github.com/vintasoftware/django-ai-plugins
npx skills add https://github.com/google/skills
npx skills add https://github.com/cloudflare/skills
npx skills add https://github.com/supabase/agent-skills
npx skills add https://github.com/planetscale/database-skills
# frontend skills
npx skills add https://github.com/vercel-labs/agent-skills
npx skills add https://github.com/vercel-labs/next-skills
# design skills
npx skills add https://github.com/openai/skills --skill frontend-skill
npx skills add https://github.com/pbakaus/impeccable
npx skills add https://github.com/nextlevelbuilder/ui-ux-pro-max-skill
npx skills add https://github.com/Leonxlnx/taste-skill
# seo/aeo skills
npx skills add https://github.com/warpdotdev/oz-skills --skill seo-aeo-audit
# video skills
npx skills add https://github.com/remotion-dev/skills
# browser skills
npx skills add https://github.com/microsoft/playwright-cli --skill playwright-cli -g
npx skills list -g
npx skills update -g
npx skills remove --all -g
Recommended:
/brainstorming from superpowers: When in doubt, start with this skill/wayfinder from mattpocock: Let AI ask you a lot of questions/find-docs from context7: Find the latest documentations/frontend-design from impeccable: The better version of the official /frontend-design skill/simplify: Run it often, you will like it/insights: Analyze your Claude Code sessions
You can find more skills on skills.sh.
MCP Servers
You probably don't need any MCP servers if you can do the same thing with CLI + skills.
Context7 MCP
No, just use the ctx7 CLI with find-docs skill instead.
npx ctx7 setup
Playwright MCP
No, you should use the playwright-cli skill instead. Both tools support headed mode (the opposite of headless), if you'd like to see the browser.
npm install -g @playwright/cli
npx skills add https://github.com/microsoft/playwright-cli
GitHub MCP
No, you should use the gh command instead.
brew install gh
Codex MCP
Yes, ironically. Other coding agents like Claude Code can use Codex via MCP, which is slightly more stable than directly invoking it with codex exec via CLI.
# Codex reads your local .codex/config.toml by default
claude mcp add codex --scope user -- codex mcp-server
However, since OpenAI releases the official Claude Code plugin: codex-plugin-cc, you should probably use that instead.
Some Other Tips
Prompt Best Practices
Command Aliases
# in ~/.zshrc
alias cc="claude"
alias ccc="claude --continue"
alias cct='tmux -CC new-session -s "claude-$(date +%s)" claude --teammate-mode tmux'
alias ccy="claude --dangerously-skip-permissions"
ccp() { claude --no-chrome --no-session-persistence -p "$*"; }
Use ccp for ad-hoc prompts:
ccp "commit"
ccp "list all .md in this repo"
Customize Your Statusline
Claude Code has a customizable statusline at the bottom of the terminal. You can run any script that outputs text.
Mine shows the current model, the current working folder, the git branch, and a grammar-corrected version of my last prompt (because my English needs all the help it can get). The grammar correction runs an ad-hoc claude command inside the statusline script.
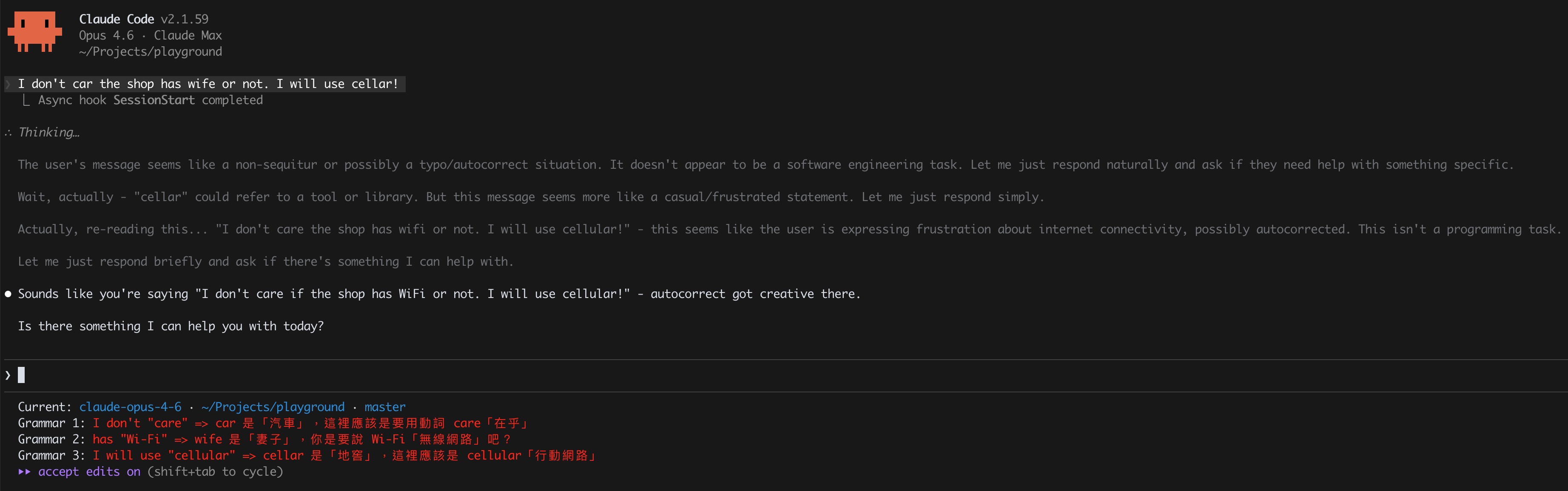
Run Ad-Hoc Claude Commands Inside Scripts
You can invoke claude as a one-shot CLI tool from hooks, statusline scripts, CI, or anywhere else. The trick is using the right flags to get a clean, isolated call with zero side effects:
cmd = """
claude
--model haiku
--max-turns 1
--setting-sources ""
--tools ""
--disable-slash-commands
--no-session-persistence
--no-chrome
--print
"""
result = subprocess.run(
[*shlex.split(cmd), your_prompt],
capture_output=True,
text=True,
timeout=15,
cwd="/tmp",
)
What each flag does:
--setting-sources "": don't load hooks (avoids infinite recursion if called from a hook)--no-session-persistence and cwd="/tmp": avoid polluting your current context--tools "": no file access, no bash, pure text in/out--no-chrome: skip the Chrome integration




